山口行治(やまぐち・ゆきはる)
 株式会社Pラーニング研究所設立準備中。元ファイザージャパン・臨床開発部門バイオメトリクス部長(臨床試験データベースシステム管理、データマネジメント、統計解析)。ダイセル化学工業株式会社、呉羽化学工業株式会社の研究開発部門で勤務。ロンドン大学St.George’s Hospital Medical SchoolでPh.D取得(薬理学)。東京大学教養学部基礎科学科卒業。中学時代から西洋哲学と現代美術にはまり、テニス部の活動を楽しんだ。冒険的なエッジを好むけれども、居心地の良いニッチの発見もそれなりに得意とする。趣味は農作業。日本科学技術ジャーナリスト会議会員。
株式会社Pラーニング研究所設立準備中。元ファイザージャパン・臨床開発部門バイオメトリクス部長(臨床試験データベースシステム管理、データマネジメント、統計解析)。ダイセル化学工業株式会社、呉羽化学工業株式会社の研究開発部門で勤務。ロンドン大学St.George’s Hospital Medical SchoolでPh.D取得(薬理学)。東京大学教養学部基礎科学科卒業。中学時代から西洋哲学と現代美術にはまり、テニス部の活動を楽しんだ。冒険的なエッジを好むけれども、居心地の良いニッチの発見もそれなりに得意とする。趣味は農作業。日本科学技術ジャーナリスト会議会員。「みんなで機械学習」第1回では、CAPDサイクル(ビジネスのPDCAサイクルを、機械学習との組み合わせでCheckから始める加速モデル)を紹介して、4回転半のゴールを設定した。前稿までのCAPDサイクル2回転目では、大量の特許データをインターネットから無料で入手して機械学習してみた。AI(人工知能)プログラムを使って「みんなで機械学習」するのはCAPDサイクルの前半で、後半は中小企業経営者が自習する。自習して「ふりだし」に戻る。「みんなで機械学習」するのは、AI技術によって近未来のビジネス環境が激変することへの準備であり、できればビジネスのチャンスにしたい。単純に言って、ほぼ全てのビジネスにおけるサービスにおいて、AI技術による自動化が導入されるだろう。AI技術にとってサービスの自動化は難しい課題ではない。ヒトよりも心地よいサービスとなるかどうかは疑問だけれども、ヒトが作り出して、ヒトが解決できない多くの社会問題・地球環境問題にチャレンジすることがAI技術に期待されているので、ヒトも機械も忙しいのだ。
CAPDサイクル3回転目では、特許データをデータマネジメントして、AI技術と共存・共生・共進化する時代のビジネスモデルを探索するためのデータベースに再構築してみよう。もちろん、そのような試みが最初から大成功することは期待していない。むしろ、実際のデータで実習しながら、データマネジメントについて学び、できれば少しでも自動化してみたい。筆者は臨床試験データのデータマネジメントと統計解析で生計を立てている。経験的には、統計解析担当者1人に対して、データマネジメント担当者は3人必要だ。データマネジメントの業務は、統計解析に使用する解析用データセットを提供することで、十分に品質管理されたデータベースから解析用データセットを作成する。データベースとデータセットの区別は、品質管理の立場からは重要なのだけれども、品質管理されたデータベースは、データベースを作成するためのデータベースシステムによって作成すると説明すると、哲学問答のようになってしまう。実際のデータマネジメント業務は、例外的なデータの処理など、マンパワーによる手作業が大半となる。この事情は機械学習でも似ていて、特に教師有り学習の場合、データベースの整備に多くの人的リソースを必要としている。
例外的なデータとしては、欠測値と外れ値が代表的だ。一見外れ値のようでも、データ入力のミスである場合もある。ランダムに発生する欠測値の場合は、様々な補完方法が工夫されている。データマネジメントとしては、未入力ではないことを確認する。外れ値の場合も、外れ値に影響されにくい統計解析の方法が工夫されている。データマネジメント業務としては、データをカテゴリー分類する、さらには標準的なコードに変換することに専門性が問われる。コーディングの問題などは、データベースを設計する段階で決定しておく必要があり、標準化には多大な努力を要する場合がある。特許データの場合でも、特許分類や出願者の名寄せなど、膨大なデータマネジメントの後に、データベースとしての検索サービスが提供されている。
統計解析と比較して、機械学習が大きな成功を示す場合は、データ解析の方法ではなく、データマネジメントの自動化が大きく寄与しているというのが筆者の作業仮説だ。例えば、デシジョン・ツリーを改良したグラディエント・ブースティングの場合、ブートストラップ法(ランダムにデータを除外して、解析を繰り返す)によって、外れ値の影響を上手(じょうず)にコントロールしている。画像識別の場合も、画像の中心化や倍率の調整など、データの前処理を自動化する効果は大きい。医療データの場合は、入手が困難で、コーディングも複雑になる。「みんなで機械学習」としては、もう少しの間、データの入手が容易で、ビジネス価値も訴求しやすい特許データにお付き合いいただきたい。特許データを統計解析する場合、特許分類のコーディングに限界があるので、「自然言語処理」が不可欠になる。しかし、「自然言語処理」は「機械学習」とともに、最重要なAI技術であって、本稿の枠組みの外になってしまう。そこで、『トリーズ(TRIZ)の発明原理40』(高木芳徳、ディスカバー・トゥエンティワン、2014年)による特許分類のもっとも単純な応用、『トリーズの9画面法』(高木芳徳、ディスカバー・トゥエンティワン、2021年)にしたがって、ビジネス関連特許の9画面表現モデルを工夫してみた。ビジネス関連特許をこのモデルに当てはめて、企業がビジネス関連特許を出願する場合に、発明を8つの基本コード(市場価値P、顧客価値、市場価値F、変化予測、技術的問題F,問題解決方法、技術的問題P、基盤構築;Pは過去Past、Fは未来Futureの略記)に分解することを試みる。基本コードに特許分類を当てはめて、簡単なキーワードを付与することで、ビジネス関連特許のデータベースを再構築する。
CAPDサイクルとビジネス関連特許の9画面表現モデルを比較してみると、顧客価値(Check)、変化予測(Action)、問題解決方法(Plan)、基盤構築(Do)が対応していて、機械学習の場合は未来志向であるため、Actionをフォローアップ・アクションではなく、変化予測と読み替えている。顧客価値を明らかにするために、顧客のビッグデータが必要になる。特許としては、問題解決方法を明らかにして、基盤技術によって実現可能にする。特許なので、改善の可能性は技術的問題(F)に絞られるので、「何が問題なのか」ということを明確にすることが最も大切だろう。現在までの技術では気が付かなかった、もしくは技術自体が生み出す問題は技術的問題(P)として、批判や反省の対象となる。このような分析モデルを使って、どのようなサービスが機械学習の対象となるのか探索してみよう。
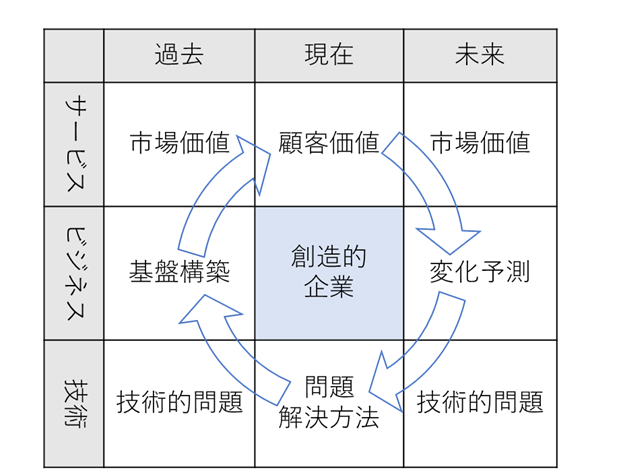
<ビジネス関連特許の9画面表現モデル>
実際のデータマネジメント作業は次回以降、アムステルダム発の無料ソフト、JASPまたはJamoviを使って実習しよう。「みんなで機械学習」するのは、簡単な問題を取り扱いたいからで、ヒトにとって簡単な問題が、機械にとっても簡単とは限らない。ヒトにとって簡単な問題を、ヒト自身が気が付いていないかもしれない。日常的な問題で、機械にとって簡単な問題を見つけることができれば、それはビジネスになるだろう。AI技術によって、多くの中小企業や小売商店の仕事が、機械(ロボット)に奪われるかもしれない。自動販売機が役立つためには、自動販売機が安全で清潔に仕事ができる環境を整える必要がある。街角には監視カメラがあり、お掃除ロボットが忙しく働き、ウイルス感染を避けて人影のない街。どこがおかしいのだろうか。「みんなで機械学習」しないかぎり、このような問題を発見して解決することはできないだろう。ヒトの能力をAIが超える時代はすでに始まっている。それは、世界最高のプロ棋士に勝利するような、AIの能力が高まるのではなく、機械と比較するヒトの能力が低くなってきているからで、生活の中にAIが役割を見いだす時代が始まっている。地球環境すら破壊してしまう認知症を生きる人類には、「みんなで機械学習」が必要不可欠なのだ。
--------------------------------------
『みんなで機械学習』は中小企業のビジネスに役立つデータ解析を、オープンソースの無料ソフトjamoviでみんなと学習します。質問があっても、絶対にニュース屋台村にはコメントしないでください。株式会社Pラーニング研究所(設立準備中)でjamoviと本稿の続き(4回転半の後)をサポートする予定です。










コメントを残す