小澤 仁(おざわ・ひとし)
 バンコック銀行執行副頭取。1977年東海銀行入行。2003年より現職。米国在住10年。バンコク在住26年。趣味:クラシック歌唱、サックス・フルート演奏。
バンコック銀行執行副頭取。1977年東海銀行入行。2003年より現職。米国在住10年。バンコク在住26年。趣味:クラシック歌唱、サックス・フルート演奏。
4 NVIDIAの企業分析
ここからは、NVIDIAがAIに使われるGPU市場において高いシェアを獲得し、また成長市場にも関わらずその地位を維持し続けている要因について解説する。NVIDIAのGPUの技術的な特徴や製品開発の歴史など、できる限り深い次元まで明らかにしたい。
4-1 事業内容・沿革・経営者
表9 NVIDIAの企業概要(2024/7時点)
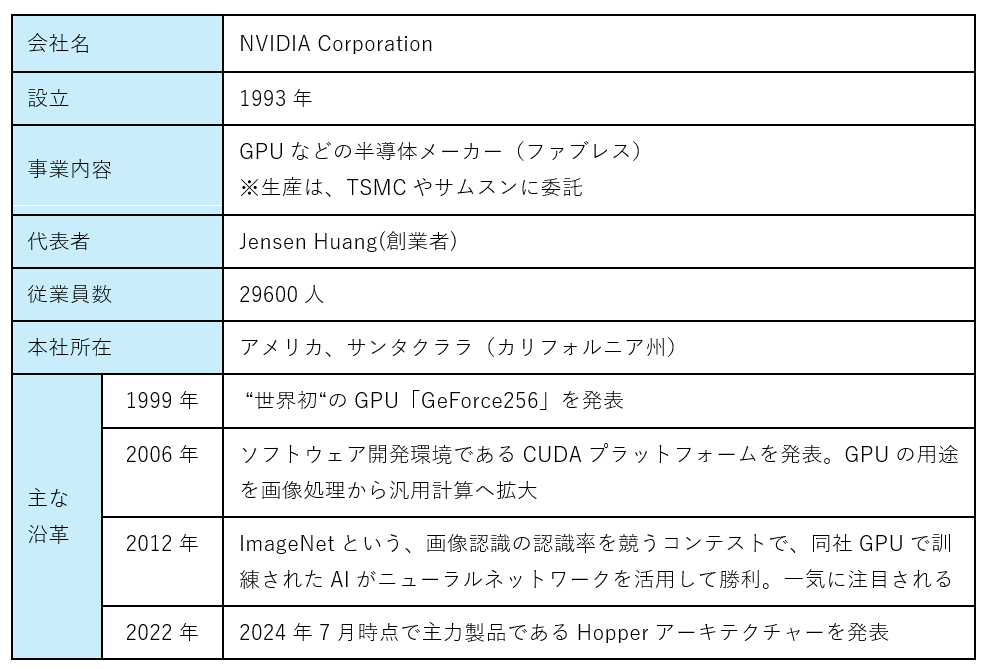
(出典)NVIDIAウェブサイトを基に筆者作成
図9 財務諸表推移
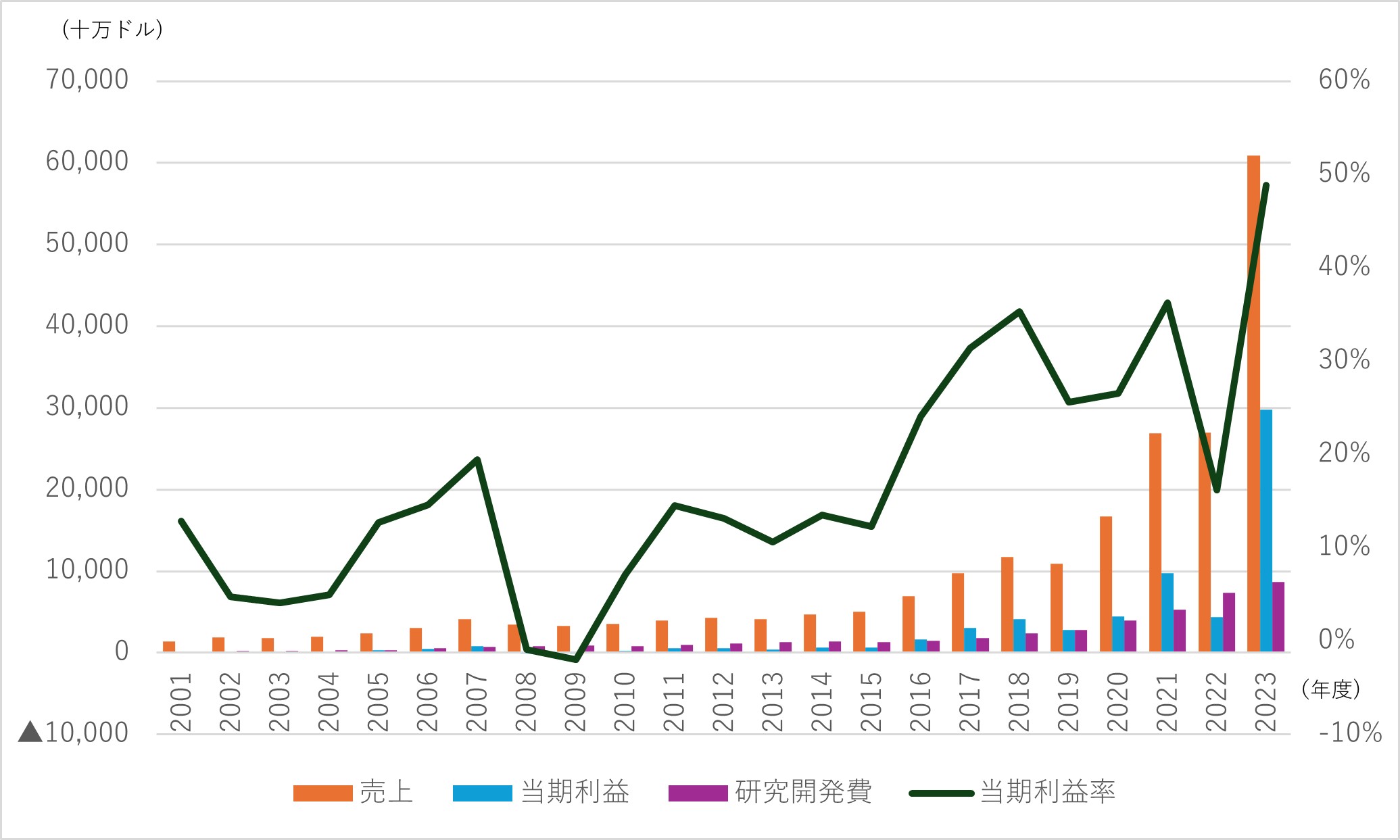
(出典)米国証券取引委員会公開資料より筆者作成
①NVIDIAは、現経営者のJensen Huang氏が1993年に設立した半導体のファブレスメーカー。GPUの開発・設計に特化し、生産は台湾のTSMCなどに委託。設立当初はゲームなどコンピューターグラフィックス用の製品が中心であったが、2006年に汎用計算(統計処理、新薬研究など)に利用可能なソフトウェア開発環境CUDAを発表。2010年代に入り、本格的にAIなどの研究開発に取り組み、2010年代後半以降は、データセンター向け市場に進出し急成長。
②財務諸表の長期推移を見ると、2010年半ばまでは平均年率売上増加率10%程度と売り上げ成長が比較的緩やかだが、2016年ごろを境に成長速度が変化。2016年から2023年までの平均年率売上増加率は3割を超える。直近2023年(2024/1期)は、前年比2.3倍と急増しているが、増加分はほぼData Center部門。特にAI需要に伴うクラウド事業者(Googleなど)向けが急増している。
③データセンター向けGPU市場では、当社以外ではAMDやIntelも市場参入しているものの、NVIDIAが8割以上のシェアを有するとされる。
図10 NVIDIAの部門別売上割合
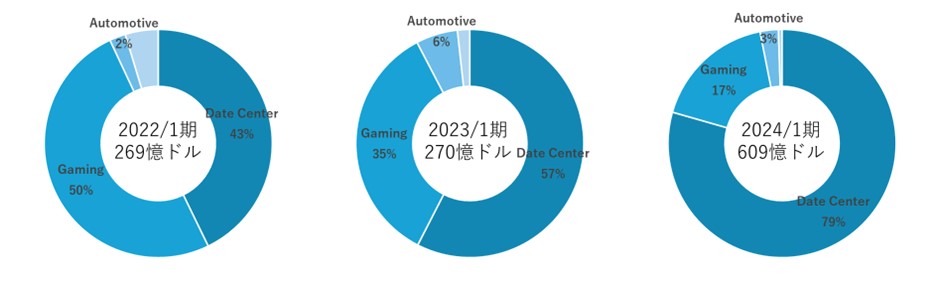
(出典)NVIDIA「2024 NVIDIA Corporation Annual Review」より筆者作成
④その他、財務諸表の長期推移からは、当期利益率が2016年ごろから上昇傾向にあり、直近2023年では50%近い数値となっていること、積極的に研究開発に投資し、過去23年間の対売上高比率が20%を超え、売上減少時も傾向として投資額を増やしていることが見て取れる。これらから、GPUの設計に特化した長期間にわたる継続かつ積極的な研究開発が、急成長するデータセンター向けGPU市場における独占的な地位、引いては高い収益性を生んだのではないかと推測される。(参考:ここまで前回第275回で既報)
4-2 NVIDIA製品開発の歴史
1993年に創業したNVIDIAは、1999年に“世界初”となるGPU「GeForce256」を開発するなど、設立当初はコンピューターグラフィックス処理用の製品を開発。その後、2003年ごろから非グラフィック分野への適用に向けた研究を開始。2006年に初めて、汎用計算用途にも使えるGPGPU製品「G80(Teslaアーキテクチャー)」を発表した。GPGPU(General-purpose computing on graphics processing unit)とは、コンピューター画面に図形や画像を描く処理をグラフィックス処理以外の様々な汎用計算用途(シミュレーション、科学計算など)に使うこと。
GPGPUとして利用する場合、これまでCPUが行っていた機能の一部(演算部分)をGPUに置き換えることで、計算の種類次第だが数倍から数百倍の速さで処理ができる可能性がある。一方、GPUは演算に特化しておりファイルの書き込みなどすらできないため、単独では使えない。当時GPGPUの利用にあたってはグラフィックス中心かつ並列の複雑なプログラミングやハードウェアの構造への理解などが必要であったため、NVIDIAは、GPUを用いた並列コンピューティングのための統合開発環境CUDAを2006年に発表(2007年に一般公開)。CUDAによってC言語などでのプログラミングが可能となるなど、開発者がGPUを利用しやすくなり、GPGPUの普及が進んだ。
表10 NVIDIAのGPU開発年表
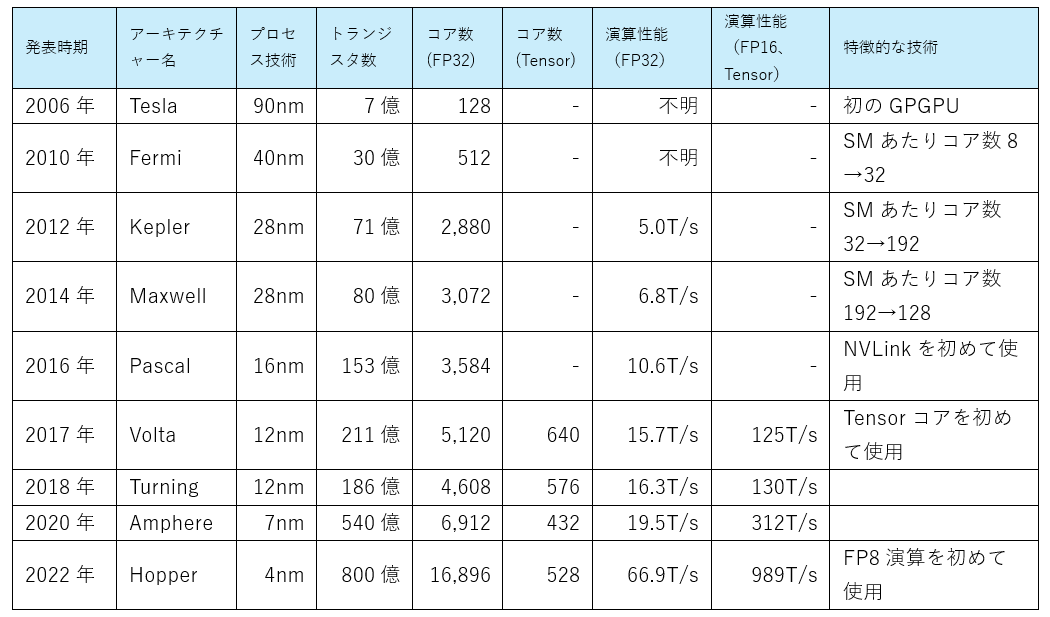
(出典)NVIDIAウェブサイトやNVIDIAに関する各種ウェブサイトより筆者作成
①NVIDIAは2006年以降、1年から2年周期程度で新たなアーキテクチャー(製品の設計構造)を発表。先端の微細化技術に基づくトランジスタ数の増大、並列処理可能なコア数の増大、メモリ容量拡充、ダイサイズの大型化などハードウェアの改良に加えて、コアの構造見直しやコア間の通信技術発展、メモリアクセスの仕組み見直しなども行ってきた。その結果、他社を圧倒する高い演算能力を持つ製品を継続的に市場に投入している。
②2016年のPascalからは、NVLinkが初めて使われている。これは、NVIDIAがIBMと共同で開発したGPU間のインターコネクト技術で複数のGPU間を高い帯域幅で直接接続可能。これによって、GPUとCPU間のデータ転送速度が5倍以上になった他、複数のGPUを同期し、一つの大きなチームとして動作させることができる。
③2017年のVoltaからは、Tensorコアが初めて使われている。これは、NVIDIA が開発した深層学習に特化した混合精度行列演算ユニット。FP16で入力した演算でFP32に近い計算結果が得られるため、計算量を増やさず高いスループットを実現できる。これは、大規模な行列計算が頻繁に行われる深層学習において、学習や推論時間短縮に大きく寄与する。
④最新の2022年発表のHopperでは、第4世代のNVLink 、第4世代のTensorコア、HBM3(最新メモリ)などが使われ、性能は著しく向上している。2006年のTeslaアーキテクチャーとの比較では、トランジスタ数・コア数は100倍以上、メモリの容量拡大や複数構造による工夫(頻繁にアクセスするデータをコアに近いメモリに事前に格納するような仕組み)、NVLinkのようなGPU間通信(複数GPU間も含む)技術利用など、大きく変化が見られ、性能が数百倍以上になっている。
4-3 NVIDIAの強み
NVIDIAは、収益性が非常に高く売上総利益率は2024/1期では73%に達する。販売価格は公開されていないものの上昇傾向にあり、最新のHopperアーキテクチャーで作られたデータセンター向け製品「H200」は約3万ドルといわれる。圧倒的な市場シェアと高い売り上げ成長率を考慮すれば、同社のGPUは「高くても性能を求めて買われている」状態にあると言える。
その同社の強固な競争優位性の源泉となる強みとは何か。設計技術や製品開発による進化などに着目して、以下の4点に分類した。以下、各項目について解説したい。
①高速演算を実現するGPUの優れたアーキテクチャー
②GPUの性能を引き出すCUDAプログラミング
③GPUの性能を向上させ続ける継続的な進化
④他社との協業などによる開発スピードの速さ
4-3-1 高速演算を実現するGPUの優れたアーキテクチャー
図11 Teslaアーキテクチャー(2006年)の製品構造
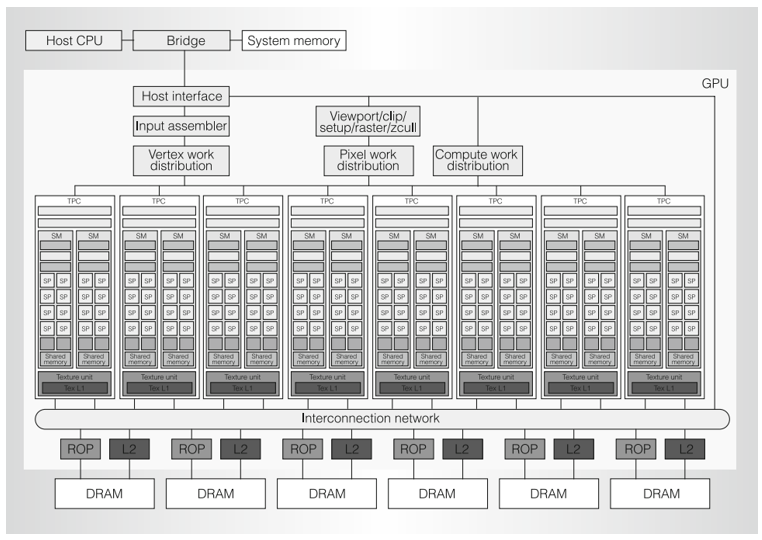
<補足>
1 SP(Streaming processor)
CUDAコアを指す
2 DRAM
メモリの1種。全SMからアクセス可能な大容量のグローバルメモリとして使われる。
3 TexL1、L2
L1キャッシュ、L2キャッシュ
4 ROP、Vertex work distribution、Pixel work distribution
グラフィックス処理に使う機能
5 Interconnection network
SM間でデータ転送するための通信ネットワーク
6 Compute work distribution
GPUの計算タスクなどを複数のSMに分配するプロセス
(出典) Erik Lindholm(NVIDIAエンジニア)など他3名「 NVIDIA TESLA:AUNIFIED GRAPHICS AND COMPUTING ARCHITECTURE」(2008年)
NVIDIAは、グラフィックス処理用として使われていたGPUの汎用計算用途での可能性にいち早く気づき、汎用計算向けのアーキテクチャーを開発。2006年のTeslaアーキテクチャーでは、グラフィックス処理用途の機構(3D画像の頂点処理などを行うための機構)も残っているが、続く2010年発表のFermi以降は汎用計算に特化した設計になっている。
演算ユニットに多くの面積を割き、CUDAコアと呼ばれる並列処理可能な演算ユニットを数百数千(先端モデルは数万)個と持つ。ただし、全てが独立して動くとプログラミング複雑化やリソース配分効率化、メモリアクセスによる遅延などの問題もあり、SMで複数のコアが協調して計算を行う仕組みを持つ。各SMがメモリやスケジュール管理機能を持つことで、計算リソースを効率的に利用している。
CUDAコアは、浮動小数点演算を高速に処理できるように設計されており、AIの深層学習などに代表される、積和演算などの比較的単純な演算を高速で処理できる。
メモリ構造も特徴的で、レジスタやキャッシュ、シェアードメモリなどの複数のメモリをチップ内部に抱える。それによって、外部のグローバルメモリへのアクセス集中やデータ移転による遅延を防ぎ、高速な演算を支えている。
4-3-2 GPUの性能を引き出すCUDAプログラミング
GPUはコア数の多さや多層のメモリ構造など構造が複雑なため、性能を引き出すためには適切なソフトウェアが必要となる。加えて、元々はグラフィック処理用に開発されたため、三次元の座標処理などを行うための専門言語が使われていた。そこで、NVIDIAは2006年に、並列コンピューティングのための統合開発環境CUDAを発表。
NVIDIAでは、ソフトウェアエンジニアの数がハードウエアエンジニアよりも多いと言われるほど、ソフトウェア開発を重視している。CUDAは他社と知見を共有せず独自に開発され、CUDAは自社製品のみでしか使えないものの、一般的なC言語などをベースに、簡単なアプリケーションで汎用計算に利用可能。その結果、多くの研究機関やエンジニアに利用されるようになり、GPGPUプログラミングの標準としての地位を確立した。
その後も、深層学習用のcuDNN、線形代数用のcuBLASなどのライブラリー開発に多額の投資を行い、さまざまな領域での自社製品の性能向上をサポート。2012年以降、深層学習が使われ始めたころには、AI研究者などにも用いられるようになった。
実際の機械学習の学習・推論などには、Tensorflow(Google)やPythorh(Meta)などのオープンソースのフレームワーク(深層学習用のより具体的な学習・検証などを行うソフトウェア。大規模言語モデルなどが実装されている)が使われることが多いが、これらはCUDAをサポートしており、バックエンドでの重い計算(例:畳み込み層の計算)を高速化するために、cuDNN などのライブラリーが内部で使われている。
2016年には、競合のAMDがCUDAのような自社GPUでの開発環境ROCmを公開。NVIDIAによる独占状況を危惧してか、GoogleなどがAMDのROCmをサポートする動きも見られる。NVIDIAによる更なるライブラリー拡充、GoogleやMetaなどの研究者との連携、他ソフトウェアへのコード移植の難しさなどから、NVIDIAによる優位性は簡単には揺るがないと思われる。
4-3-3 GPUの性能を向上させ続ける継続的な進化
図12 Hopperアーキテクチャー(2022年)の製品構造
図12-1 アーキテクチャーの全体像
 図12-2 GPCの構造(全体で8つのGPCを持つ)
図12-2 GPCの構造(全体で8つのGPCを持つ)
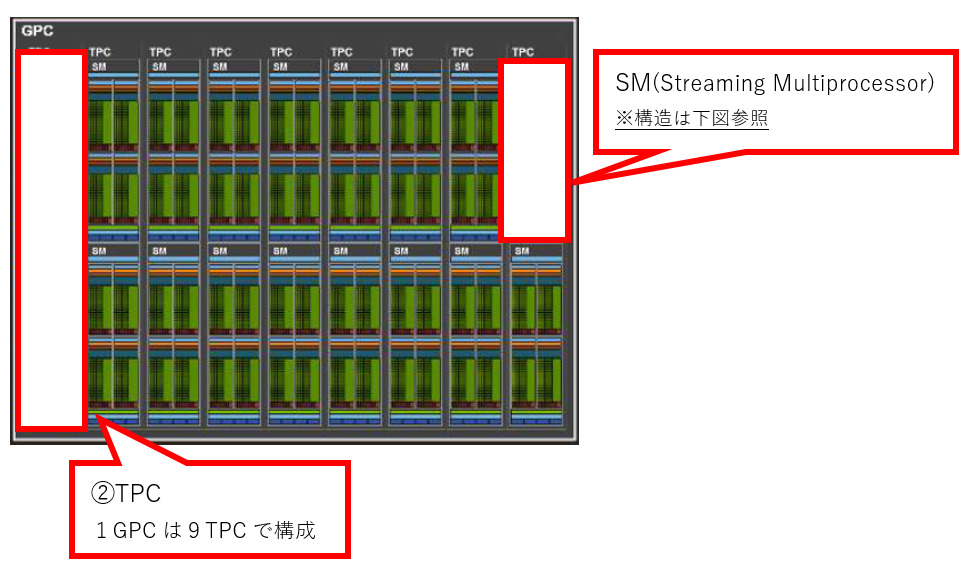
図12-3 SMの構造(全体では、144のSMを持つ)
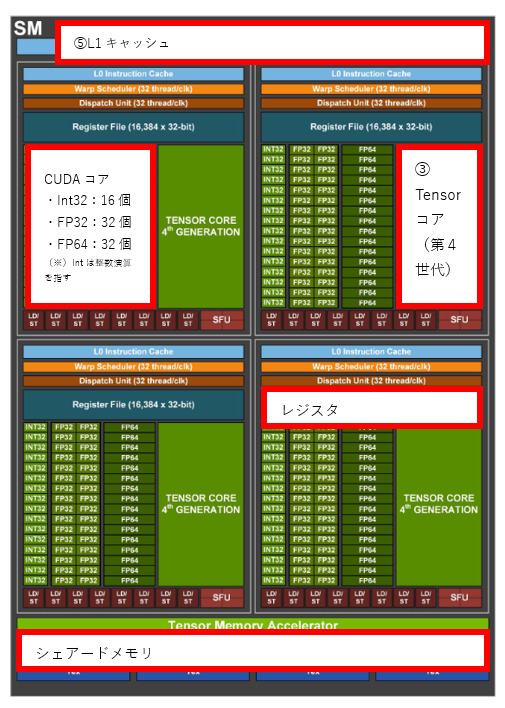
(出典)NVIDIA「NVIDIA H100 Tensor Core GPU Architecture」
表11 NVIDIA製GPUの機能解説
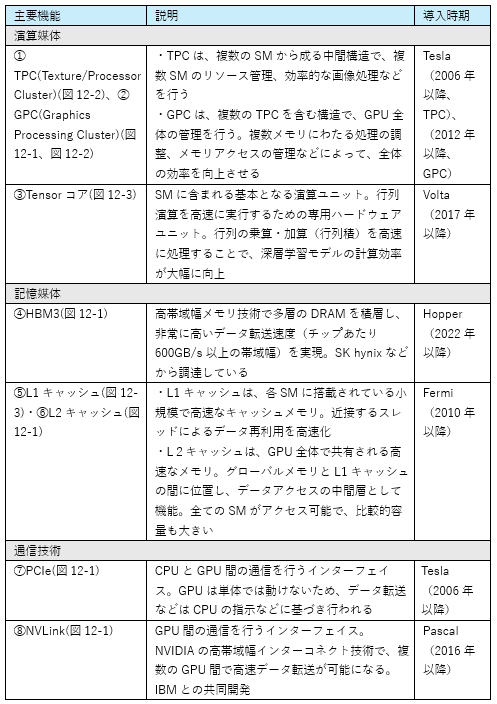
(出典)GPUに関する各社ウェブサイトから筆者作成
NVIDIAは、2006年のTeslaアーキテクチャーとCUDA発表以降も、短期間で新たな技術などを用いた製品を逐次市場へ投入。常に市場のリーダーとしての地位を維持してきた。その中で、競争優位につながったと思われる特徴的な技術などを紹介する。
①Tensorコア
図13 Tensorコアの行列演算例(4×4の融合積和演算)
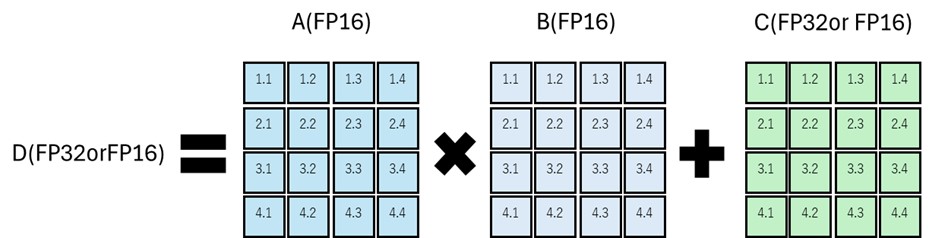
(出典)NVIDIAウェブサイトより筆者作成
NVIDIAが開発した深層学習に特化した混合精度行列演算ユニット。深層学習での演算においては、相対的な変化が重要で精度の高さは優先度が低い点に着目。主流だったFP32より劣るFP16を用いた、計算量を増やさず高いスループットを実現できる仕組みを開発した。これは、大規模な行列計算が頻繁に行われる深層学習において、学習や推論時間短縮に大きく寄与する。
原理としては、FP32の行列が三つあった場合、行列積をFP16、和をFP32で実行。負荷のかかる積をFP16で行うため行列積は低精度であるため計算負荷が小さく、和は高精度なため追加の誤差が生じない。更に専用回路(Tensorコア)で実行するため、一つの命令で多くの演算を処理できる。例えばH100(Hopperアーキテクチャー)では単純なFP32が 66.9TLOPSであるのに対し、FP16の低精度積でTensorコアを使った場合は989TFLOPS すなわち15倍の演算速度となる。
アーキテクチャー別に進化を遂げており、Hopperアーキテクチャーでは、第4世代が使われている。第4世代では、FP8コアを追加。それ以前のFP16の積和演算と比べ、精度は落ちるものの2倍の演算速度となっている。
②NVLink
NVIDIAがIBMと共同で開発したGPU間のインターコネクト技術で、ポイント・ツー・ポイント(中継ポイントなどを経由しない)で、デバイス間の専用リンクを使用。複数のGPU間を高い帯域幅で直接接続可能。これによって、それ以前と比べGPUとCPU間のデータ転送速度が5倍以上になったほか、複数のGPUを同期し一つの大きなチームとして動作させることができるようになった。
NVLinkもアーキテクチャー別に進化しており、Hopperアーキテクチャーでは第4世代が使われる。2つのペアを使用し各方向に25GB/秒の有効帯域幅を持つNVLink が18個使われ、最大合計900GB/秒を実現している。
4-3-4 他社との協業などによる開発スピードの速さ
GPUの製品開発を取り巻く環境として、生産面では微細化進展による設計複雑化や製造技術の高度化などが挙げられる。また、需要面では、文章作成などの生成AIや自動運転など膨大な演算を必要とするサービスの需要拡大などが挙げられる。そのような環境下では、「市場の期待に沿う高性能な製品をいかに早く開発できるか」が重要になる。
GPUでも、1年単位で新製品が発売されるなど、開発から製品化までが非常に短サイクル化している。数百億個ものトランジスタ数から成る設計を手作業で行うのは膨大な時間を要するため、EDAと呼ばれる設計支援ソフトウェアの利用は必須。その他、GPUの性能向上に伴い消費電力が増大しており、HopperアーキテクチャーのH100では1台で最大700Wもの電力を消費。演算性能あたりの電力効率は向上しているものの、GPU1台あたりの絶対量は増加傾向にある。熱量コントロールや消費電力削減が求められており、熱解析などでEDAのノウハウ活用は必要。また、高度な技術を扱うためファウンドリなどとの擦り合わせも非常に重要となってくる。
EDA市場は、チップレット技術(製造時の歩留まり改善のために、小さなチップを複数まとめて一つのパッケージに収める技術)や更なる微細化など、設計複雑化や技術高度化などを背景にプレーヤーの大型化が進んでいる。現状EDA市場は積極的なM&Aにより、大手2社への集約化が進んでいる。その中で、Synopsys によるAnsys買収、CadenceによるNUMECA買収などから、熱解析などの分野が重要視されていることがわかる。
図14 EDAベンダー市場シェア(2021年)
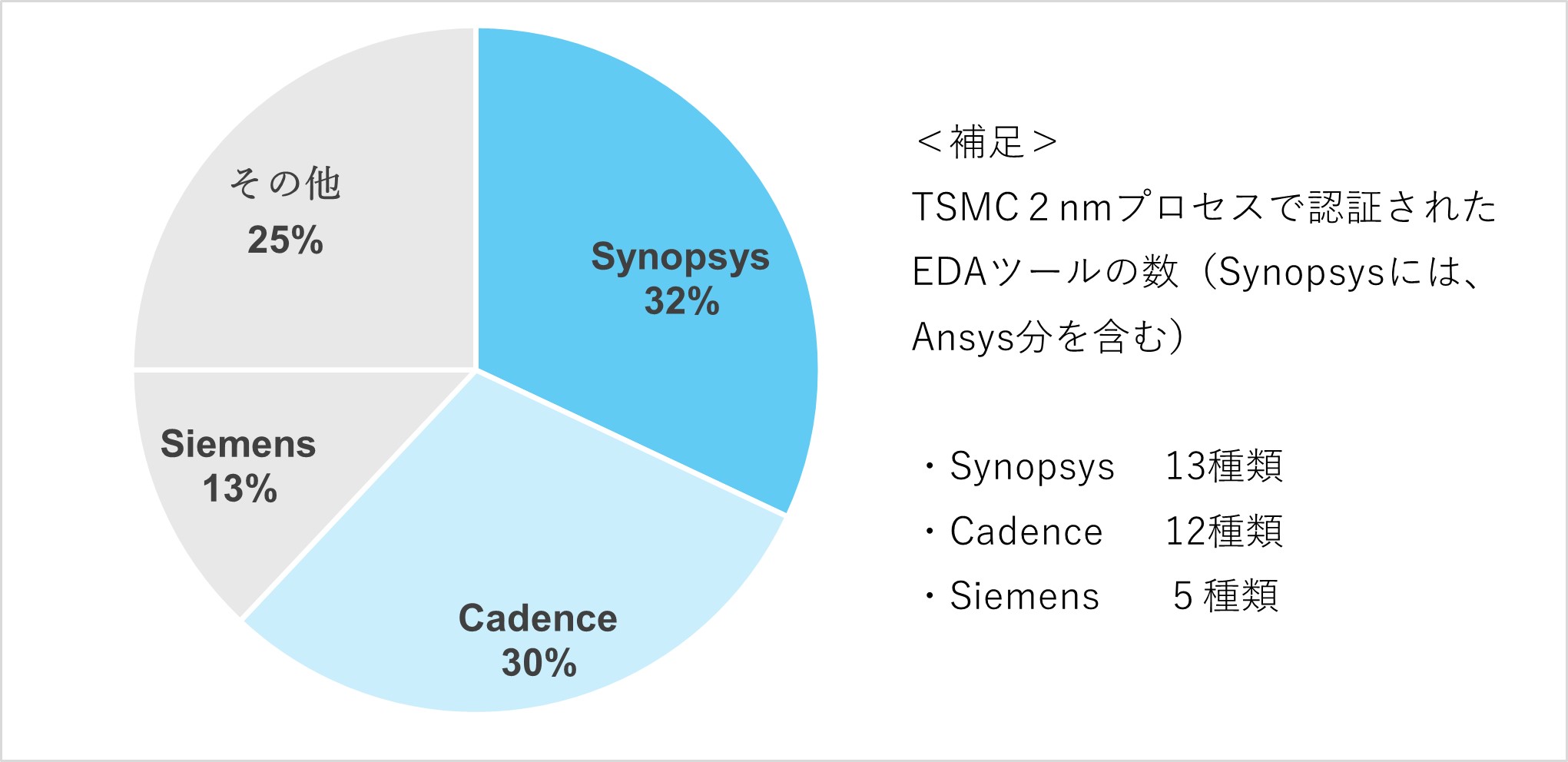
(出典)台湾TrendForceによる調査結果を基に筆者作成
表12 大手EDAベンダー2社による主要買収事例
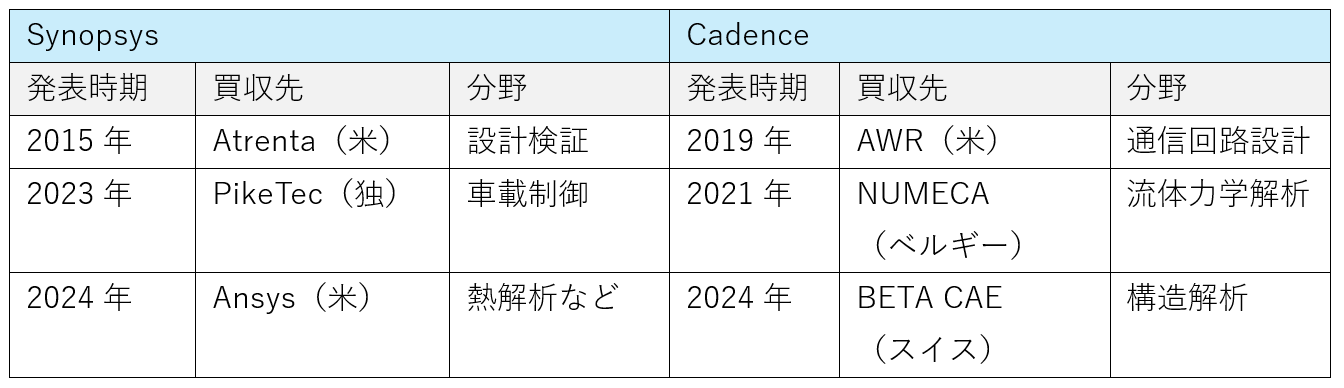
(出典)Synopsys、Cadenceウェブサイトを基に筆者作成
NVIDIAは、ファウンドリであるTSMC、EDAベンダーのSynopsysやCadenceなど外部プレーヤーと積極的に協業。開発段階から関与することで最先端のノウハウを活用。加えてNVIDIAは、EDAベンダーやファウンドリへ自社のGPUやAIノウハウなどを提供。膨大な変数を変化させながら最適な組み合わせを見つける設計工程では、AI活用などで作業時間を短縮。例えば、膨大な演算が必要になる露光工程では、露光条件の微調整に自社開発のアルゴリズムなどを活用。このように、自社にない技術は積極的に外部と協業することで、開発スピード向上につなげている。
その他、NVIDIAの組織は非常にフラットに作られており、社内の情報共有と意思決定を早くする工夫がされている。Jensun Huang CEOは内部の情報共有をいかに早くするかを重要視。組織構造では、3から4層の管理職層を排して、CEOの直属の部下は50人前後にも上るという。また、社内のどの役職でも情報や会議へアクセス可能となっているもようだ。このような組織構造や経営者の思想などが開発スピードにも影響を与えたと考えられる。
5 まとめ
(1)2010年代以降、AI技術が急速に発展している。AI自身が膨大なデータを学習することでルールやパターンを自ら探し出す機械学習が、データ流通量増大や半導体性能向上に伴い実用化。AIを用いた画像処理や音声認識、自然言語処理などは既に様々な分野で使われており、2022年に公開されたChatGPTに代表される生成AIなどの利用も急速に広がっている。今後についても、瞬時にカメラやセンサーなどから取得したデータを基に瞬時に判断を下す自動運転(自動車産業)や、手術時に瞬時に適切な処置を提案(最終的には実行)するようなロボットやシステム(医療産業)、軍事用の無人機操縦(軍需産業)など、幅広い分野で、膨大な演算量を高速に処理する高度なAI技術の活用が予想される。
(2)AI技術で重要な機械学習には高性能な半導体は不可欠。特に深層学習では、一つひとつの演算は単純だが膨大な演算量が必要となる。深層学習には、複雑な処理は苦手だが並列処理に強みを持つGPUが使われている。AI市場は今後も急速に成長のため、AIに使われるGPU市場は今後も年率3割を超える高い成長が見込まれる。
(3)GPU市場で優位性を持つ企業がNVIDIA。元々はグラフィックス処理などを専用に行うGPUを開発していたが、2006年以降汎用計算用途にも使える製品を開発。2010年代に入ってからはAIの研究などにも注力し、現在はAI半導体の標準としての地位を築いた。AIなどで使われる先端GPU市場では8割以上のシェアを持つ。
(4)NVIDIAの強みは、大きく次の4点に分けられると考える。①高速演算を実現するGPUの優れたアーキテクチャー②GPUの性能を引き出すCUDAプログラミング③GPUの性能を向上させ続ける継続的な進化④他社との協業等による開発スピードの速さ。優れたハードウェアだけでなく、研究者やエンジニアなど利用者にとって使い勝手の良いソフトウェア開発環境を提供したこと、そのハードウェアやソフトウェアの性能を速いスピードで持続的に向上させ続けていることで、高い市場シェアと高収益を実現したと考えられる。
(5)なお、NVIDIAの成長と裏腹に日本の半導体産業は凋落(ちょうらく)を続けている。現在の日本の保有技術を「設計・製造」「ロジック・メモリ・その他」で分類した場合、特にロジックに課題を持つ。設計技術において、積層を重ねていくメモリと比べた場合、ロジックは設計の自由度が高くより複雑な回路設計などが必要。日本が先端ロジックの設計技術を持たない要因は様々あるが、微細化など技術が高度化し、外部のEDAツール活用の重要性が増していた中、日本は自前のツール開発などに拘ったことで遅れを取ったことはその一因。現在、日本はラピダスに代表されるように、国を挙げて半導体産業復興を図っているが、NVIDIAやTSMCなどトップ企業が20年以上の年月をかけて培った技術に追いつくのは容易ではない。日本がNVIDIAのような最先端の設計技術を持てるようにするためには、「過去の成功体験を忘れ、トップ企業から人材を招へいするなどして学び、まずは優れた技術を模倣(もほう)すること」「ソフトウェアへの理解と投資」などが必要と考える。
※『バンカーの目のつけどころ 気のつけどころ』過去の関連記事は以下の通り
第275回「世界最先端の半導体会社NVIDIAの技術の強み(その1)」(2024年9月 20日付)
第225回「日本の半導体について考えてみる」(2022年9月23日付)
https://www.newsyataimura.com/ozawa-102/#more-13295










コメントを残す